Submitted by admin on 2017, April 12, 2:54 PM
//var url = "http://www.test.net/install.html";
var url = "http://www.test.net/t.php";
var param = "name=david&age=30";
var obj = new ActiveXObject("WinHttp.WinHttpRequest.5.1");
obj.Open("GET", url, false);
obj.Option(4) = 13056;
obj.Option(6) = false; //false可以不自动跳转,截取服务端返回的302状态。
obj.setRequestHeader("Content-Type","application/x-www-form-urlencoded");
obj.setRequestHeader("Referer", "http://www.baidu.com");
obj.setRequestHeader("User-Agent","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322)");
//obj.setRequestHeader("REMOTE_ADDR","1.1.1.8");
//obj.setRequestHeader("CLIENT-IP","1.1.1.3");
obj.setRequestHeader("X-FORWARDED-FOR","1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.4,1.1.1.41.1.1.4");
//obj.setRequestHeader("HTTP_CLIENT_IP","1.1.1.5");
//obj.setRequestHeader("X-ClientIP","1.1.1.6");
//obj.setRequestHeader("HTTP_X_FORWARDED_FOR","1.1.1.7");
obj.setRequestHeader("REMOTE_ADDR","1.1.1.8");
obj.setRequestHeader("X-Real-IP","1.1.1.9");
obj.setRequestHeader("X-REAL-IP","1.1.1.11");
obj.Send(param);
WScript.Echo(obj.responseText);
js代码 | 评论:0
| Trackbacks:0
| 阅读:853
Submitted by admin on 2017, March 10, 11:41 AM
网站程序 | 评论:0
| Trackbacks:0
| 阅读:806
Submitted by admin on 2017, February 21, 11:49 PM
background-size
设置背景图片的大小,以长度值或百分比显示,还可以通过cover和contain来对图片进行伸缩。
语法:
background-size: auto | <长度值> | <百分比> | cover | contain
取值说明:
1、auto:默认值,不改变背景图片的原始高度和宽度;
2、<长度值>:成对出现如200px 50px,将背景图片宽高依次设置为前面两个值,当设置一个值时,将其作为图片宽度值来等比缩放;
3、<百分比>:0%~100%之间的任何值,将背景图片宽高依次设置为所在元素宽高乘以前面百分比得出的数值,当设置一个值时同上;
4、cover:顾名思义为覆盖,即将背景图片等比缩放以填满整个容器;
5、contain:容纳,即将背景图片等比缩放至某一边紧贴容器边缘为止。
提示:大家可以在右边的编辑窗口输入自己的代码尝试不同取值的效果。
杂七杂八 | 评论:0
| Trackbacks:0
| 阅读:766
Submitted by admin on 2017, February 18, 8:43 PM
- #!/bin/bash
-
- step=2 #间隔的秒数,不能大于60
-
- for (( i = 0; i < 60; i=(i+step) )); do
- echo "OK"
- sleep $step
- done
-
- exit 0
#!/bin/bash
step=3
for (( i = 0; i < 60; i=(i+step) )); do
id=`ps ax | grep ".php" | grep -v grep | awk -F" " '{print $1}'`
echo $id
if [ "$id"x = x ];then
echo "no"
else
sleep 1
nid=`ps ax | grep ".php" | grep -v grep | awk -F" " '{print $1}'`
if [ "$id" == "$nid" ];then
echo $nid
kill $id
fi
echo $id
fi
sleep $step
done
exit 0
linux | 评论:0
| Trackbacks:0
| 阅读:780
Submitted by admin on 2017, February 10, 4:29 PM
select
golang 的 select 就是监听 IO 操作,当 IO 操作发生时,触发相应的动作。
在执行select语句的时候,运行时系统会自上而下地判断每个case中的发送或接收操作是否可以被立即执行【立即执行:意思是当前Goroutine不会因此操作而被阻塞,还需要依据通道的具体特性(缓存或非缓存)】
- 每个case语句里必须是一个IO操作
- 所有channel表达式都会被求值、所有被发送的表达式都会被求值
- 如果任意某个case可以进行,它就执行(其他被忽略)。
- 如果有多个case都可以运行,Select会随机公平地选出一个执行(其他不会执行)。
- 如果有default子句,case不满足条件时执行该语句。
- 如果没有default字句,select将阻塞,直到某个case可以运行;Go不会重新对channel或值进行求值。
select 语句用法
注意到 select 的代码形式和 switch 非常相似, 不过 select 的 case 里的操作语句只能是【IO 操作】 。
此示例里面 select 会一直等待等到某个 case 语句完成, 也就是等到成功从 ch1 或者 ch2 中读到数据,如果都不满足条件且存在default case, 那么default case会被执行。 则 select 语句结束。
示例:
package main import ( "fmt" ) func main(){ ch1 := make(chan int, 1) ch2 := make(chan int, 1) select { case e1 := <-ch1: fmt.Printf("1th case is selected. e1=%v",e1) case e2 := <-ch2: fmt.Printf("2th case is selected. e2=%v",e2) default: fmt.Println("default!.") } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
select分支选择规则
所有跟在case关键字右边的发送语句或接收语句中的通道表达式和元素表达式都会先被求值。无论它们所在的case是否有可能被选择都会这样。
求值顺序:自上而下、从左到右
示例:
package main import ( "fmt" ) var ch1 chan int var ch2 chan int var chs = []chan int{ch1, ch2} var numbers = []int{1,2,3,4,5} func main(){ select { case getChan(0) <- getNumber(2): fmt.Println("1th case is selected.") case getChan(1) <- getNumber(3): fmt.Println("2th case is selected.") default: fmt.Println("default!.") } } func getNumber(i int) int { fmt.Printf("numbers[%d]\n", i) return numbers[i] } func getChan(i int) chan int { fmt.Printf("chs[%d]\n", i) return chs[i] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
输出:
chs[0]
numbers[2]
chs[1]
numbers[3]
default!.
可以看出求值顺序。满足自上而下、自左而右这条规则。
随机执行case
如果同时有多个case满足条件,通过一个伪随机的算法决定哪一个case将会被执行。
示例:
package main import ( "fmt" ) func main(){ chanCap := 5 ch7 := make(chan int, chanCap) for i := 0; i < chanCap; i++ { select { case ch7 <- 1: case ch7 <- 2: case ch7 <- 3: } } for i := 0; i < chanCap; i++ { fmt.Printf("%v\n", <-ch7) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出:(注:每次运行都会不一样)
3
3
2
3
1
一些惯用手法示例
示例一:单独启用一个Goroutine执行select,等待通道关闭后结束循环
package main import ( "fmt" "time" ) func main(){ ch11 := make(chan int, 1000) sign := make(chan int, 1) for i := 0; i < 1000; i++ { ch11 <- i } close(ch11) go func(){ var e int ok := true for{ select { case e,ok = <- ch11: if !ok { fmt.Println("End.") break } fmt.Printf("ch11 -> %d\n",e) } if !ok { sign <- 0 break } } }() <- sign }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
ch11 -> 0
ch11 -> 1
…
ch11 -> 999
End.
示例二:加以改进,我们不想等到通道被关闭后再退出循环,利用一个辅助通道模拟出操作超时。
package main import ( "fmt" "time" ) func main(){ ch11 := make(chan int, 1000) sign := make(chan int, 1) for i := 0; i < 1000; i++ { ch11 <- i } close(ch11) timeout := make(chan bool,1) go func(){ time.Sleep(time.Millisecond) timeout <- false }() go func(){ var e int ok := true for{ select { case e,ok = <- ch11: if !ok { fmt.Println("End.") break } fmt.Printf("ch11 -> %d\n",e) case ok = <- timeout: fmt.Println("Timeout.") break } if !ok { sign <- 0 break } } }() <- sign }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
ch11 -> 0
ch11 -> 1
…
ch11 -> 691
Timeout.
示例三:上面实现了单个操作的超时,但是那个超时触发器开始计时有点早。
package main import ( "fmt" "time" ) func main(){ ch11 := make(chan int, 1000) sign := make(chan int, 1) for i := 0; i < 1000; i++ { ch11 <- i } go func(){ var e int ok := true for{ select { case e,ok = <- ch11: if !ok { fmt.Println("End.") break } fmt.Printf("ch11 -> %d\n",e) case ok = <- func() chan bool { timeout := make(chan bool,1) go func(){ time.Sleep(time.Millisecond) timeout <- false }() return timeout }(): fmt.Println("Timeout.") break } if !ok { sign <- 0 break } } }() <- sign }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
ch11 -> 0
ch11 -> 1
…
ch11 -> 999
Timeout.
非缓冲的Channel
我们在初始化一个通道时将其容量设置成0,或者直接忽略对容量的设置,那么就称之为非缓冲通道
ch1 := make(chan int, 1) ch2 := make(chan int, 0) ch3 := make(chan int)
- 向此类通道发送元素值的操作会被阻塞,直到至少有一个针对该通道的接收操作开始进行为止。
- 从此类通道接收元素值的操作会被阻塞,直到至少有一个针对该通道的发送操作开始进行为止。
- 针对非缓冲通道的接收操作会在与之相应的发送操作完成之前完成。
对于第三条要特别注意,发送操作在向非缓冲通道发送元素值的时候,会等待能够接收该元素值的那个接收操作。并且确保该元素值被成功接收,它才会真正的完成执行。而缓冲通道中,刚好相反,由于元素值的传递是异步的,所以发送操作在成功向通道发送元素值之后就会立即结束(它不会关心是否有接收操作)。
示例一
实现多个Goroutine之间的同步
package main import ( "fmt" "time" ) func main(){ unbufChan := make(chan int) go func(){ fmt.Println("Sleep a second...") time.Sleep(time.Second) num := <- unbufChan fmt.Printf("Received a integer %d.\n", num) }() num := 1 fmt.Printf("Send integer %d...\n", num) unbufChan <- num fmt.Println("Done.") }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
缓冲channel输出结果如下:
Send integer 1…
Done.
======================
非缓冲channel输出结果如下:
Send integer 1…
Sleep a second…
Received a integer 1.
Done.
在非缓冲Channel中,从打印数据可以看出主Goroutine中的发送操作在等待一个能够与之配对的接收操作。配对成功后,元素值1才得以经由unbufChan通道被从主Goroutine传递至那个新的Goroutine.
select与非缓冲通道
与操作缓冲通道的select相比,它被阻塞的概率一般会大很多。只有存在可配对的操作的时候,传递元素值的动作才能真正的开始。
示例:
发送操作间隔1s,接收操作间隔2s
分别向unbufChan通道发送小于10和大于等于10的整数,这样更容易从打印结果分辨出配对的时候哪一个case被选中了。下列案例两个case是被随机选择的。
package main import ( "fmt" "time" ) func main(){ unbufChan := make(chan int) sign := make(chan byte, 2) go func(){ for i := 0; i < 10; i++ { select { case unbufChan <- i: case unbufChan <- i + 10: default: fmt.Println("default!") } time.Sleep(time.Second) } close(unbufChan) fmt.Println("The channel is closed.") sign <- 0 }() go func(){ loop: for { select { case e, ok := <-unbufChan: if !ok { fmt.Println("Closed channel.") break loop } fmt.Printf("e: %d\n",e) time.Sleep(2 * time.Second) } } sign <- 1 }() <- sign <- sign }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
default! //无法配对
e: 1
default!//无法配对
e: 3
default!//无法配对
e: 15
default!//无法配对
e: 17
default!//无法配对
e: 9
The channel is closed.
Closed channel.
default case会在收发操作无法配对的情况下被选中并执行。在这里它被选中的概率是50%。
- 上面的示例给予了我们这样一个启发:使用非缓冲通道能够让我们非常方便地在接收端对发送端的操作频率实施控制。
- 可以尝试去掉default case,看看打印结果,代码稍作修改如下:
package main import ( "fmt" "time" ) func main(){ unbufChan := make(chan int) sign := make(chan byte, 2) go func(){ for i := 0; i < 10; i++ { select { case unbufChan <- i: case unbufChan <- i + 10: } fmt.Printf("The %d select is selected\n",i) time.Sleep(time.Second) } close(unbufChan) fmt.Println("The channel is closed.") sign <- 0 }() go func(){ loop: for { select { case e, ok := <-unbufChan: if !ok { fmt.Println("Closed channel.") break loop } fmt.Printf("e: %d\n",e) time.Sleep(2 * time.Second) } } sign <- 1 }() <- sign <- sign }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
e: 0
The 0 select is selected
e: 11
The 1 select is selected
e: 12
The 2 select is selected
e: 3
The 3 select is selected
e: 14
The 4 select is selected
e: 5
The 5 select is selected
e: 16
The 6 select is selected
e: 17
The 7 select is selected
e: 8
The 8 select is selected
e: 19
The 9 select is selected
The channel is closed.
Closed channel.
总结:上面两个例子,第一个有default case 无法配对时执行该语句,而第二个没有default case ,无法配对case时select将阻塞,直到某个case可以运行(上述示例是直到unbufChan数据被读取操作),不会重新对channel或值进行求值。
golang | 评论:0
| Trackbacks:0
| 阅读:819
Submitted by admin on 2017, February 10, 3:55 PM
golang 的 select 的功能和 select, poll, epoll 相似, 就是监听 IO 操作,当 IO 操作发生时,触发相应的动作。
示例:
ch1 := make (chan int, 1) ch2 := make (chan int, 1) ... select { case <-ch1: fmt.Println("ch1 pop one element") case <-ch2: fmt.Println("ch2 pop one element") }
注意到 select 的代码形式和 switch 非常相似, 不过 select 的 case 里的操作语句只能是【IO 操作】 。
此示例里面 select 会一直等待等到某个 case 语句完成, 也就是等到成功从 ch1 或者 ch2 中读到数据。 则 select 语句结束。
【使用 select 实现 timeout 机制】
如下:
timeout := make (chan bool, 1) go func() { time.Sleep(1e9) // sleep one second timeout <- true }() ch := make (chan int) select { case <- ch: case <- timeout: fmt.Println("timeout!") }
当超时时间到的时候,case2 会操作成功。 所以 select 语句则会退出。 而不是一直阻塞在 ch 的读取操作上。 从而实现了对 ch 读取操作的超时设置。
下面这个更有意思一点。
当 select 语句带有 default 的时候:
ch1 := make (chan int, 1) ch2 := make (chan int, 1) select { case <-ch1: fmt.Println("ch1 pop one element") case <-ch2: fmt.Println("ch2 pop one element") default: fmt.Println("default") }
此时因为 ch1 和 ch2 都为空,所以 case1 和 case2 都不会读取成功。 则 select 执行 default 语句。
就是因为这个 default 特性, 我们可以使用 select 语句来检测 chan 是否已经满了。
如下:
ch := make (chan int, 1) ch <- 1 select { case ch <- 2: default: fmt.Println("channel is full !") }
因为 ch 插入 1 的时候已经满了, 当 ch 要插入 2 的时候,发现 ch 已经满了(case1 阻塞住), 则 select 执行 default 语句。 这样就可以实现对 channel 是否已满的检测, 而不是一直等待。
比如我们有一个服务, 当请求进来的时候我们会生成一个 job 扔进 channel, 由其他协程从 channel 中获取 job 去执行。 但是我们希望当 channel 瞒了的时候, 将该 job 抛弃并回复 【服务繁忙,请稍微再试。】 就可以用 select 实现该需求。
关于垃圾回收
c++ 写久了的人, 刚接触 golang 的时候最不能理解的就是为什么作者要支持垃圾回收。 不管是从垃圾回收器的实现上看, 还是对于程序员编程习惯的养成方面, 都避免不了编写出的程序性能损失。 但是写了几天 golang 之后, 又觉得有垃圾回收确实大大减轻程序员的心智负担, 降低编程门槛,提高编程效率。 让我联想到 汇编 和 C语言 的关系, 即使 C语言的性能不如汇编写出来的高, 但是后者还是颠覆了前者。
golang | 评论:0
| Trackbacks:0
| 阅读:845
Submitted by admin on 2017, February 10, 3:33 PM
刚才看golang的sync的包,看见一个很有用的功能。就是WaitGroup。
先说说WaitGroup的用途:它能够一直等到所有的goroutine执行完成,并且阻塞主线程的执行,直到所有的goroutine执行完成。
这里要注意一下,他们的执行结果是没有顺序的,调度器不能保证多个 goroutine 执行次序,且进程退出时不会等待它们结束。
WaitGroup总共有三个方法:Add(delta int),Done(),Wait()。简单的说一下这三个方法的作用。
Add:添加或者减少等待goroutine的数量
Done:相当于Add(-1)
Wait:执行阻塞,直到所有的WaitGroup数量变成0
如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
for i := 0; i > 5; i = i + 1 {
wg.Add(1)
go func(n int) {
defer wg.Add(-1)
EchoNumber(n)
}(i)
}
wg.Wait()
}
func EchoNumber(i int) {
time.Sleep(3e9)
fmt.Println(i)
}
|
golang中的同步是通过sync.WaitGroup来实现的.WaitGroup的功能:它实现了一个类似队列的结构,可以一直向队列中添加任务,当任务完成后便从队列中删除,如果队列中的任务没有完全完成,可以通过Wait()函数来出发阻塞,防止程序继续进行,直到所有的队列任务都完成为止.
WaitGroup的特点是Wait()可以用来阻塞直到队列中的所有任务都完成时才解除阻塞,而不需要sleep一个固定的时间来等待.但是其缺点是无法指定固定的goroutine数目.但是其缺点是无法指定固定的goroutine数目.可能通过使用channel解决此问题。
另一个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package main
import (
"fmt"
"sync"
)
var waitgroup sync.WaitGroup
func Afunction(shownum int) {
fmt.Println(shownum)
waitgroup.Done()
}
func main() {
for i := 0; i < 10; i++ {
waitgroup.Add(1)
go Afunction(i)
}
waitgroup.Wait()
}
|
http://studygolang.com/articles/2027
golang | 评论:0
| Trackbacks:0
| 阅读:897
Submitted by admin on 2017, January 10, 7:27 PM
SSDP 简单服务发现协议,是应用层协议,是构成UPnP(通用即插即用)技术的核心协议之一。它为网络客户端(network client)提供了一种发现网络服务(network services)的机制,采用基于通知和发现路由的多播方式实现。
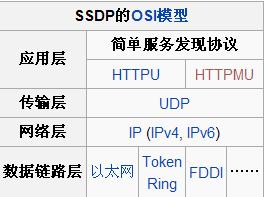
SSDP多播地址:239.255.255.250:1900(IPv4),FF0x::C(IPv6)
两种类型的SSDP请求消息会通过SSDP多播地址发送:
1. 发现请求(Discovery request 或查询请求)。SSDP客户端向此地址发送HTTP UDP 发现请求,查询某种类型的服务。SSDP服务在此地址上监听服务发现请求。当服务监听到的HTTP UDP 发现请求和它自己提供的服务匹配时,它以单播方式发送HTTP UDP 响应。
2. 存在通知(notification)。SSDP服务向此多播地址发送HTTP UDP 通知消息来宣布自己的存在。
发现结果(discovery results)和存在通知消息(presence announcements)提供的信息包括:
服务的类型URI
服务名称USN:唯一标识一种服务实例。
位置信息:发现结果和存在通知可包含一个或多个位置URI,客户端利用位置信息可以找到它需要的服务。
期限信息:客户端在自己的cache中保存此服务多长时间。如果期限过了,关于此服务的信息会被从cache中拿掉。当客户端接收到的发现结果或存在通知包含的USN和cache中的某条匹配,则更新。
客户端的服务缓存像下面这样:

【SSDP发现请求】ssdp:discover
ssdp:discover 必须包含一个ST头,客户端使用ST头来表明他们想发现的服务类型。ssdp:discover 必须包含一个带 * 的请求URI。
M-SEARCH * HTTP/1.1
S: uuid:ijklmnop-7dec-11d0-a765-00a0c91e6bf6
Host: 239.255.255.250:1900
Man: "ssdp:discover"
ST: ge:fridge
MX: 3
各HTTP协议头的含义:
HOST:设置为协议保留多播地址和端口,必须是:239.255.255.250:1900(IPv4)或FF0x::C(IPv6)
MAN:设置协议查询的类型,必须是:ssdp:discover
MX:设置设备响应最长等待时间。设备响应在0和这个值之间随机选择响应延迟的值,这样可以为控制点响应平衡网络负载。
ST:设置服务查询的目标,它必须是下面的类型:
-ssdp:all 搜索所有设备和服务
-upnp:rootdevice 仅搜索网络中的根设备
-uuid:device-UUID 查询UUID标识的设备
-urn:schemas-upnp-org:device:device-Type:version 查询device-Type字段指定的设备类型,设备类型和版本由UPNP组织定义。
-urn:schemas-upnp-org:service:service-Type:version 查询service-Type字段指定的服务类型,服务类型和版本由UPNP组织定义。
SSDP服务发现自己的服务类型和ST中指明的服务类型匹配时,可以向ssdp:discover来自的IP地址/端口响应。响应消息应该包含服务的位置信息(Location 或AL头),ST和USN头。响应消息应该包含cache控制信息(max-age 或者 Expires头),如果两者都包含了,Expires 头优先,如果两者都缺失,那么这条服务消息不能被cache。
HTTP/1.1 200 OK
S: uuid:ijklmnop-7dec-11d0-a765-00a0c91e6bf6
Ext:
Cache-Control: no-cache="Ext", max-age = 5000
ST: ge:fridge
USN: uuid:abcdefgh-7dec-11d0-a765-00a0c91e6bf6
AL: <blender:ixl><http://foo/bar>
各HTTP协议头的含义简介:
CACHE-CONTROL:max-age指定通知消息存活时间,如果超过此时间间隔,控制点可以认为设备不存在
DATE:指定响应生成的时间
EXT:向控制点确认MAN头域已经被设备理解
LOCATION:包含根设备描述得URL地址
SERVER:饱含操作系统名,版本,产品名和产品版本信息
ST:内容和意义与查询请求的相应字段相同
USN:表示不同服务的统一服务名,它提供了一种标识出相同类型服务的能力。
【SSDP存在通知消息】
SSDP服务通过存在通知消息来向客户端宣布自己的存在,更新期限信息,更新位置信息。
ssdp:alive 消息必须将 NT 设置成自己的服务类型,USN头设置成自己的USN。ssdp:alive 应该包括Location或者AL头,如果没有DNS支持的话,使用SSDP服务的IP地址来代表位置。ssdp:alive还应该包括cache控制信息,max-age或者Expires头。
NOTIFY * HTTP/1.1
Host: 239.255.255.250:reservedSSDPport
NT: blenderassociation:blender
NTS: ssdp:alive
USN: someunique:idscheme3
AL: <blender:ixl><http://foo/bar>
Cache-Control: max-age = 7393
ssdp:alive 没有响应消息。
SSDP服务可以发送ssdp:byebye 来宣布自己下线。ssdp:byebye 必须将NT设置成自己的服务类型,将USN头设置成自己的USN。ssdp:byebye 也没有响应消息。当客户端接收到ssdp:byebye 消息,删掉cache里面的相关条目。
NOTIFY * HTTP/1.1
Host: 239.255.255.250:reservedSSDPport
NT: someunique:idscheme3
NTS: ssdp:byebye
USN: someunique:idscheme3
【SSDP Auto-Shut-Off Algorithm】
A mechanism is needed to ensure that SSDP does not cause such a high level of traffic that it overwhelms the network it is running on.
【ssdp:all】
A mechanism is needed to enable a client to enumerate all the services available on a particular SSDP multicast channel/port.
【参考】
SSDP 协议原文:http://tools.ietf.org/html/draft-cai-ssdp-v1-03
http://www.cnblogs.com/debin/archive/2009/12/01/1614543.html
传输协议 | 评论:0
| Trackbacks:0
| 阅读:998
