查看mysql库大小,表大小,索引大小
https://www.cnblogs.com/xzlive/p/9884674.html
在内存中建立 MySQL 的临时目录
https://www.oschina.net/question/12_79459
MySQL高负载解决方案
https://www.cnblogs.com/pengai/articles/9190979.html
Submitted by admin on 2020, February 21, 11:59 PM
https://www.cnblogs.com/xzlive/p/9884674.html
Submitted by admin on 2018, July 4, 12:36 AM
记得以前,当出现:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction,
要解决是一件麻烦的事情 ;
特别是当一个SQL执行完了,但未COMMIT,后面的SQL想要执行就是被锁,超时结束;
DBA光从数据库无法着手找出源头是哪个SQL锁住了;
有时候看看show engine innodb status , 并结合 show full processlist; 能暂时解决问题;但一直不能精确定位;
在5.5中,information_schema 库中增加了三个关于锁的表(MEMORY引擎);
innodb_trx ## 当前运行的所有事务
innodb_locks ## 当前出现的锁
innodb_lock_waits ## 锁等待的对应关系
看到这个就非常激动 ; 这可是解决了一个大麻烦,先来看一下表结构
https://blog.csdn.net/mangmang2012/article/details/9207007
Submitted by admin on 2018, July 4, 12:35 AM
set autocommit=0指事务非自动提交,自此句执行以后,每个SQL语句或者语句块所在的事务都需要显示"commit"才能提交事务。
1、不管autocommit 是1还是0
START TRANSACTION 后,只有当commit数据才会生效,ROLLBACK后就会回滚。
2、当autocommit 为 0 时
不管有没有START TRANSACTION。
只有当commit数据才会生效,ROLLBACK后就会回滚。
3、如果autocommit 为1 ,并且没有START TRANSACTION 。
调用ROLLBACK是没有用的。即便设置了SAVEPOINT。
Submitted by admin on 2018, June 14, 9:24 AM
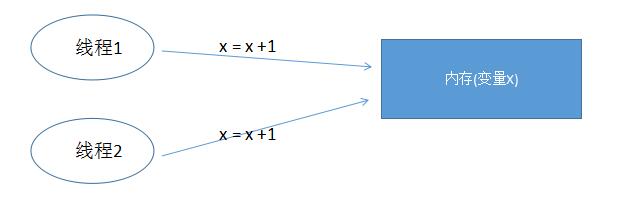
我们知道,在单机的“线程模型“中,2个线程并发修改一个变量,是需要加锁的。这个在Java并发编程–序列1已经讲过,要么是悲观锁,要么是乐观锁。
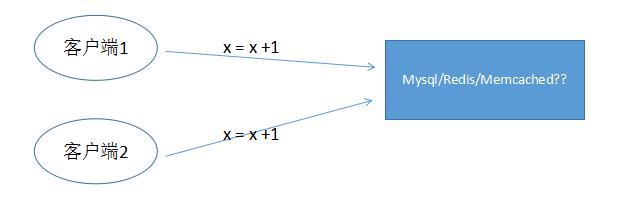
如果把单机的线程模型,改成有客户端/服务器的进程模型。服务器可以是Mysql/Redis/Memcached任何一种,那该问题又如何解决呢?
Mysql: 用类似update table set x = x + 1 where … 这样的单条语句就可解决上述问题,因为服务器内部会处理加锁的问题,不用客户端解决。
Memcached: incr/decr命令
Redis: incr/decr命令
一句话:对于这种简单的整数加减的原子操作,只要是1条命令可以搞定,就不需要客户端解决互斥问题。
上面的方案1,必须是单条命令,但该方法有很大局限性。很多时候,如果我们需要执行复杂的计算逻辑,要先把数据get出来,执行复杂逻辑,再set回去。类似下面这种:
此时有2条指令,没有办法保证2条语句的原子性,这个时候如何解决呢?
关于Mysql解决上述问题的乐观锁方案,此处不再详述,参见Java并发编程-序列1
Memcached提供了2个命令 gets + cas。gets取出数据的时候,同时返回版本号;修改之后, cas回去的时候,会比较该版本号和服务器上最新的版本号。如果不等,则cas失败。
Redis提供了watch命令,如下所示:
Redis也提供了事务的概念,但它不能回滚。如果1条命令执行错误,会继续执行下面的。
此处的multi/extc,类似Mysql中的beganTransaction/endTransaction。
另外,由于redis是单线程的,因此事务里面的多条语句执行时,不会被打断。
我们都知道, Memcached内部是多线程的,而Redis是单线程的。多线程好理解,但Redis为什么要搞成单线程呢?
个人认为,有以下几个原因:
(1)redis有各种复杂的数据结构list, has, set。也就是说,对于一个(key, value),value的类型可以是list, hash, set。在实际应用场景中,很容易出现多个客户端对同一个key的这个复杂的value数据结构进行并发操作,如果是多线程,势必要引入锁,而锁却是性能杀手。
相比较而言,memcached只有简单的get/set/add操作,没有复杂数据结构,在互斥这个问题上,没有redis那么严重。
(2)对于纯内存操作来说,cpu并不是瓶颈,瓶颈在网络IO上。所以即使单线程,也很快。另外,如果要利用多核的优势,可以在一个机器上开多个redis实例。
Submitted by admin on 2018, June 14, 9:20 AM
最近因为在工作中需要,学习了乐观锁与悲观锁的相关知识,这里我通过这篇文章,把我自己对这两个“锁家”兄弟理解记录下来;
- 悲观锁:正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)的修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
以常用的mysql InnoDB存储引擎为例:加入商品表items表中有一个字段status,status=1表示该商品未被下单,status=2表示该商品已经被下单,那么我们对每个商品下单前必须确保此商品的status=1。假设有一件商品,其id为10000;如果不使用锁,那么操作方法如下:
//查出商品状态
select status from items where id=10000;
//根据商品信息生成订单
insert into orders(id,item_id) values(null,10000);
//修改商品状态为2
update Items set status=2 where id=10000;
上述场景在高并发环境下可能出现问题:
前面已经提到只有商品的status=1是才能对它进行下单操作,上面第一步操作中,查询出来的商品status为1。但是当我们执行第三步update操作的时候,有可能出现其他人先一步对商品下单把Item的status修改为2了,但是我们并不知道数据已经被修改了,这样就可能造成同一个商品被下单2次,使得数据不一致。所以说这种方式是不安全的。
使用悲观锁来实现:在上面的场景中,商品信息从查询出来到修改,中间有一个处理订单的过程,使用悲观锁的原理就是,当我们在查询出items信息后就把当前的数据锁定,直到我们修改完毕后再解锁。那么在这个过程中,因为items被锁定了,就不会出现有第三者来对其进行修改了。
注:要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。我们可以使用命令设置MySQL为非autocommit模式:
set autocommit=0;
设置完autocommit后,我们就可以执行我们的正常业务了。具体如下:
//开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//查询出商品信息
select status from items where id=10000 for update;
//根据商品信息生成订单
insert into orders (id,item_id) values (null,10000);
//修改商品status为2
update items set status=2 where id=10000;
//提交事务
commit;/commit work;
注:上面的begin/commit为事务的开始和结束,因为在前一步我们关闭了mysql的autocommit,所以需要手动控制事务的提交,在这里就不细表了。
上面的第一步我们执行了一次查询操作:select status from items where id=10000 for update;与普通查询不一样的是,我们使用了select…for update的方式,这样就通过数据库实现了悲观锁。此时在items表中,id为10000的 那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
注:需要注意的是,在事务中,只有SELECT ... FOR UPDATE 或LOCK IN SHARE MODE 同一笔数据时会等待其它事务结束后才执行,一般SELECT ... 则不受此影响。拿上面的实例来说,当我执行select status from items where id=10000 for update;后。我在另外的事务中如果再次执行select status from items where id=10000 for update;则第二个事务会一直等待第一个事务的提交,此时第二个查询处于阻塞的状态,但是如果我是在第二个事务中执行select status from items where id=10000;则能正常查询出数据,不会受第一个事务的影响。
上面我们提到,使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认Row-Level Lock,所以只有明确地指定主键,MySQL 才会执行Row lock (只锁住被选取的数据) ,否则MySQL 将会执行Table Lock (将整个数据表单给锁住)。除了主键外,使用索引也会影响数据库的锁定级别。
悲观锁并不是适用于任何场景,它也有它存在的一些不足,因为悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。如果加锁的时间过长,其他用户长时间无法访问,影响了程序的并发访问性,同时这样对数据库性能开销影响也很大,特别是对长事务而言,这样的开销往往无法承受。所以与悲观锁相对的,我们有了乐观锁,乐观锁的概念如下:
- 乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。那么我们如何实现乐观锁呢,一般来说有以下2种方式:
1.使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值+1。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。用下面的一张图来说明:

如上图所示,如果更新操作顺序执行,则数据的版本(version)依次递增,不会产生冲突。但是如果发生有不同的业务操作对同一版本的数据进行修改,那么,先提交的操作(图中B)会把数据version更新为2,当A在B之后提交更新时发现数据的version已经被修改了,那么A的更新操作会失败。
2.乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
以mysql InnoDB存储引擎为例,还是拿之前的例子商品表items表中有一个字段status,status=1表示该商品未被下单,status=2表示该商品已经被下单,那么我们对每个商品下单前必须确保此商品的status=1。假设有一件商品,其id为10000;
下单操作包括3步骤:
//查询出商品信息
select (status,version) from items where id=#{id}
//根据商品信息生成订单
//修改商品status为2
update items set status=2,version=version+1 where id=#{id} and version=#{version};
为了使用乐观锁,我们需要首先修改items表,增加一个version字段,数据默认version可设为1;
其实我们周围的很多产品都有乐观锁的使用,比如我们经常使用的分布式存储引擎XXX,XXX中存储的每个数据都有版本号,版本号在每次更新后都会递增,相应的,在XXX put接口中也有此version参数,这个参数是为了解决并发更新同一个数据而设置的,这其实就是乐观锁;
很多情况下,更新数据是先get,修改get回来的数据,然后put回系统。如果有多个客户端get到同一份数据,都对其修改并保存,那么先保存的修改就会被后到达的修改覆盖,从而导致数据一致性问题,在大部分情况下应用能够接受,但在少量特殊情况下,这个是我们不希望发生的。
比如系统中有一个值”1”, 现在A和B客户端同时都取到了这个值。之后A和B客户端都想改动这个值,假设A要改成12,B要改成13,如果不加控制的话,无论A和B谁先更新成功,它的更新都会被后到的更新覆盖。XXX引入的乐观锁机制避免了这样的问题。刚刚的例子中,假设A和B同时取到数据,当时版本号是10,A先更新,更新成功后,值为12,版本为11。当B更新的时候,由于其基于的版本号是10,此时服务器会拒绝更新,返回version error,从而避免A的更新被覆盖。B可以选择get新版本的value,然后在其基础上修改,也可以选择强行更新。
Submitted by admin on 2017, December 24, 3:53 PM
今天王总又给我们上了一课,其实mysql处理高并发,防止库存超卖的问题,在去年的时候,王总已经提过;但是很可惜,即使当时大家都听懂了,但是在现实开发中,还是没这方面的意识。今天就我的一些理解,整理一下这个问题,并希望以后这样的课程能多点。
先来就库存超卖的问题作描述:一般电子商务网站都会遇到如团购、秒杀、特价之类的活动,而这样的活动有一个共同的特点就是访问量激增、上千甚至上万人抢购一个商品。然而,作为活动商品,库存肯定是很有限的,如何控制库存不让出现超买,以防止造成不必要的损失是众多电子商务网站程序员头疼的问题,这同时也是最基本的问题。
从技术方面剖析,很多人肯定会想到事务,但是事务是控制库存超卖的必要条件,但不是充分必要条件。
举例:
总库存:4个商品
请求人:a、1个商品 b、2个商品 c、3个商品
程序如下:
beginTranse(开启事务)
try{
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount > 0){
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
以上代码就是我们平时控制库存写的代码了,大多数人都会这么写,看似问题不大,其实隐藏着巨大的漏洞。数据库的访问其实就是对磁盘文件的访问,数据库中的表其实就是保存在磁盘上的一个个文件,甚至一个文件包含了多张表。例如由于高并发,当前有三个用户a、b、c三个用户进入到了这个事务中,这个时候会产生一个共享锁,所以在select的时候,这三个用户查到的库存数量都是4个,同时还要注意,mysql innodb查到的结果是有版本控制的,再其他用户更新没有commit之前(也就是没有产生新版本之前),当前用户查到的结果依然是就版本;
然后是update,假如这三个用户同时到达update这里,这个时候update更新语句会把并发串行化,也就是给同时到达这里的是三个用户排个序,一个一个执行,并生成排他锁,在当前这个update语句commit之前,其他用户等待执行,commit后,生成新的版本;这样执行完后,库存肯定为负数了。但是根据以上描述,我们修改一下代码就不会出现超买现象了,代码如下:
beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount < 0){
throw new Exception('库存不足');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
另外,更简洁的方法:
beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where amount>=quantity and postID = 12345');
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
=====================================================================================
1、在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成性能问题的
必须使用缓存,将需要秒杀的商品放入缓存中,并使用锁来处理其并发情况。当接到用户秒杀提交订单的情况下,先将商品数量递减(加锁/解锁)后再进行其他方面的处理,处理失败在将数据递增1(加锁/解锁),否则表示交易成功。
当商品数量递减到0时,表示商品秒杀完毕,拒绝其他用户的请求。
2、这个肯定不能直接操作数据库的,会挂的。直接读库写库对数据库压力太大,要用缓存。
把你要卖出的商品比如10个商品放到缓存中;然后在memcache里设置一个计数器来记录请求数,这个请求书你可以以你要秒杀卖出的商品数为基数,比如你想卖出10个商品,只允许100个请求进来。那当计数器达到100的时候,后面进来的就显示秒杀结束,这样可以减轻你的服务器的压力。然后根据这100个请求,先付款的先得后付款的提示商品以秒杀完。
3、首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。
这个直接可以使用加锁机制去解决,乐观锁或者悲观锁。
乐观锁,就是在数据库设计一个版本号的字段,每次修改都使其+1,这样在提交时比对提交前的版本号就知道是不是并发提交了,但是有个缺点就是只能是应用中控制,如果有跨应用修改同一条数据乐观锁就没办法了,这个时候可以考虑悲观锁。
悲观锁,就是直接在数据库层面将数据锁死,类似于oralce中使用select xxxxx from xxxx where xx=xx for update,这样其他线程将无法提交数据。
除了加锁的方式也可以使用接收锁定的方式,思路是在数据库中设计一个状态标识位,用户在对数据进行修改前,将状态标识位标识为正在编辑的状态,这样其他用户要编辑此条记录时系统将发现有其他用户正在编辑,则拒绝其编辑的请求,类似于你在操作系统中某文件正在执行,然后你要修改该文件时,系统会提醒你该文件不可编辑或删除。
4、不建议在数据库层面加锁,建议通过服务端的内存锁(锁主键)。当某个用户要修改某个id的数据时,把要修改的id存入memcache,若其他用户触发修改此id的数据时,读到memcache有这个id的值时,就阻止那个用户修改。
5、实际应用中,并不是让mysql去直面大并发读写,会借助“外力”,比如缓存、利用主从库实现读写分离、分表、使用队列写入等方法来降低并发读写。
Submitted by admin on 2017, May 11, 5:10 PM
mysqld_safe --skip-grant-tables --socket=/tmp/mysql.sock > /dev/null 2>&1 &
Submitted by admin on 2016, December 16, 11:07 AM
wget http://mirrors.sohu.com/mysql/MySQL-5.7/mysql-5.7.12.tar.gz

| « 2026年03月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
[11] [1] [20] [47] [5] [8] [4] [5] [9] [62] [7] [2] [30] [1] [27] [5] [6] [5] [3] [24] [2] [17] [59] [71] [230] [16] [64] [11] [2] [3] [7] [9] [1] [10] [3] [14] [32] [16] [2] [4] [17] [2] [2] [8] [12] [6] [3] [15] [8] [3] [9] [1] [81] [2] [4] [5] [16] [3] [4] [18] [1]