Submitted by admin on 2011, July 7, 6:25 PM
This article is focusing installing and configure MRTG with CPU,Memory and Disk Usage Graphs examples for Debian Ubuntu and Kubuntu Users and may be work for some debian based distributions.
MRTG is Multi Router Traffic Grapher (MRTG) is a tool to monitor the traffic load on network links. MRTG generates HTML pages containing PNG images which provide a LIVE visual representation of this traffic.
MRTG Requirements
Apache webserver with perl support
NET-SNMP
GD
Libpng
zlib
If you want to download MRTG you can download from here
Preparing you System for MRTG Instalaltion
First you need to install the required compilers
#apt-get install gcc make g++
Apache 2 Installation with perl support
Follow these instructions to install apache2 with perl support
MRTG Installation
Now we need to install mrtg and snmp
Installing MRTG in Debian, Ubuntu and Kubuntu
#apt-get install mrtg snmpd
The installation will create an mrtg subdirectory where the Apache Web pages reside. On your Debian,ubnutu,kubuntu systems the path of this subdirectory is:
/var/www/mrtg
Now you need to edit the mrtg configuration file to edit the some of the settings
File is located at /etc/mrtg.cfg you need to change the global settings as follows
# Global Settings
RunAsDaemon: yes
EnableIPv6: no
WorkDir: /var/www/mrtg
Options[_]: bits,growright
WriteExpires: Yes
Title[^]: Traffic Analysis for
You will find a crontab running every 5 minutes as user root
# cat /etc/cron.d/mrtg
0-55/5 * * * * root if [ -x /usr/bin/mrtg ] && [ -r /etc/mrtg.cfg ]; then env LANG=C /usr/bin/mrtg /etc/mrtg.cfg >> /var/log/mrtg/mrtg.log 2>&1; fi
Now we need to assign the snmp community name in snmp configration file /etc/snmp/snmpd.conf
# sec.name source community
# com2sec paranoid default public
com2sec readonly default public
#com2sec readwrite default private
Now you need to restart the snmp service
#/etc/init.d/snmpd restart
The configuration file creating using
#cfgmaker public@localhost > /etc/mrtg.cfg
Creating a configuration file for a device using cfgmaker
#cfgmaker public@192.168.0.1 >> /etc/mrtg.cfg
With the configuration file created correctly there’s only one other thing you have to do and that’s to use the indexmaker utility to create the summary home page. Since you have to re-run this command every time you make certain changes to the /etc/mrtg.cfg configuration file.
Creating index file for the webserver using indexmaker
#indexmaker /etc/mrtg.cfg > /var/www/mrtg/index.html
Now you need to reboot your system wait for five minutes or so and then take a look at your summary home page. If your Debian,ubuntu,kubuntu system’s IP address is 192.168.0.1 then you’d type in the following in the address bar of a browser running on a system on the same network:
http://192.168.0.1/mrtg/
Your summary home page should come up with a graph for each target entry in the configuration file. If a graph looks like there’s no data on it, click on it and check the statistics to see if any traffic is being seen. Small amounts of traffic won’t show up on the graphs because we used the Unscaled statement
Some of examples how to monitor cpu , memory , Disk usage
CPU Usage
/etc/mrtg/cpu.cfg
WorkDir: /var/www/mrtg
LoadMIBs: /usr/share/snmp/mibs/UCD-SNMP-MIB.txt
Target[localhost.cpu]:ssCpuRawUser.0&ssCpuRawUser.0:public@127.0.0.1+ ssCpuRawSystem.0&ssCpuRawSystem.0:public@127.0.0.1+
ssCpuRawNice.0&ssCpuRawNice.0:public@127.0.0.1
RouterUptime[localhost.cpu]: public@127.0.0.1
MaxBytes[localhost.cpu]: 100
Title[localhost.cpu]: CPU Load
PageTop[localhost.cpu]: Active CPU Load %
Unscaled[localhost.cpu]: ymwd
ShortLegend[localhost.cpu]: %
YLegend[localhost.cpu]: CPU Utilization
Legend1[localhost.cpu]: Active CPU in % (Load)
Legend2[localhost.cpu]:
Legend3[localhost.cpu]:
Legend4[localhost.cpu]:
LegendI[localhost.cpu]: Active
LegendO[localhost.cpu]:
Options[localhost.cpu]: growright,nopercent
Memory Usage
/etc/mrtg/mem.cfg
LoadMIBs: /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt
Target[localhost.mem]: .1.3.6.1.4.1.2021.4.6.0&.1.3.6.1.4.1.2021.4.6.0:public@localhost
PageTop[localhost.mem]:Free Memory
WorkDir: /var/www/mrtg
Options[localhost.mem]: nopercent,growright,gauge,noinfo
Title[localhost.mem]: Free Memory
MaxBytes[localhost.mem]: 1000000
kMG[localhost.mem]: k,M,G,T,P,X
YLegend[localhost.mem]: bytes
ShortLegend[localhost.mem]: bytes
LegendI[localhost.mem]: Free Memory:
LegendO[localhost.mem]:
Legend1[localhost.mem]: Free memory, not including swap, in bytes
Memory Monitoring (Total Versus Available Memory)
/etc/mrtg/memfree.cfg
LoadMIBs: /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt
Target[server.memory]: memAvailReal.0&memTotalReal.0:public@localhost
Title[server.memory]: Free Memory
PageTop[server.memory]: < H1 >Free Memory< /H1 >
MaxBytes[server.memory]: 100000000000
ShortLegend[server.memory]: B
YLegend[server.memory]: Bytes
LegendI[server.memory]: Free
LegendO[server.memory]: Total
Legend1[server.memory]: Free memory, not including swap, in bytes
Legend2[server.memory]: Total memory
Options[server.memory]: gauge,growright,nopercent
kMG[server.memory]: k,M,G,T,P,X
Memory Monitoring (Percentage usage)
/etc/mrtg/mempercent.cfg
LoadMIBs: /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt
Title[server.mempercent]: Percentage Free Memory
PageTop[server.mempercent]: < H1 >Percentage Free Memory< /H1 >
Target[server.mempercent]: ( memAvailReal.0&memAvailReal.0:publicy@localhost ) * 100 / ( memTotalReal.0&memTotalReal.0:public@localhost )
options[server.mempercent]: growright,gauge,transparent,nopercent
Unscaled[server.mempercent]: ymwd
MaxBytes[server.mempercent]: 100
YLegend[server.mempercent]: Memory %
ShortLegend[server.mempercent]: Percent
LegendI[server.mempercent]: Free
LegendO[server.mempercent]: Free
Legend1[server.mempercent]: Percentage Free Memory
Legend2[server.mempercent]: Percentage Free Memory
Disk Usage
/etc/mrtg/disk.cfg
LoadMIBs: /usr/share/snmp/mibs/HOST-RESOURCES-MIB.txt
Target[server.disk]: dskPercent.1&dskPercent.2:public@localhost
Title[server.disk]: Disk Partition Usage
PageTop[server.disk]: < H1 >Disk Partition Usage /home and /var< /H1 >
MaxBytes[server.disk]: 100
ShortLegend[server.disk]: %
YLegend[server.disk]: Utilization
LegendI[server.disk]: /home
LegendO[server.disk]: /var
Options[server.disk]: gauge,growright,nopercent
Unscaled[server.disk]: ymwd
Creating jobs for CPU , Memory and Disk Usage
CPU
/etc/cron.mrtg/cpu
#!/bin/sh
/usr/bin/mrtg /etc/mrtg/cpu.cfg
Memory
/etc/cron.mrtg/mem
#!/bin/sh
/usr/bin/mrtg /etc/mrtg/mem.cfg
Memory Free
/etc/cron.mrtg/memfree
#!/bin/sh
/usr/bin/mrtg /etc/mrtg/memfree.cfg
Memory Percentage
/etc/cron.mrtg/mempercent
#!/bin/sh
/usr/bin/mrtg /etc/mrtg/mempercent.cfg
Disk
/etc/cron.mrtg/disk
#!/bin/sh
/usr/bin/mrtg /etc/mrtg/disk.cfg
Run each script 3 times (disregard the warnings)
/etc/cron.mrtg/cpu
/etc/cron.mrtg/mem
/etc/cron.mrtg/memfree
/etc/cron.mrtg/mempercent
/etc/cron.mrtg/disk
Make the Index Files
#/usr/bin/indexmaker --output=/var/www/mrtg/index.html \
--title=”Memory and CPU Usage ” \
--sort=name \
--enumerate \
/etc/mrtg/cpu.cfg \
/etc/mrtg/mem.cfg \
/etc/cron.mrtg/memfree \
/etc/cron.mrtg/mempercent \
/etc/cron.mrtg/disk
Make the mrtg.cfg file
#cfgmaker --global “WorkDir: /var/www/mrtg/” \
--global “Options[_]: growright,bits” \
--ifref=ip \
public@localhost > /etc/mrtg/mrtg.conf
Cronjob setup
/bin/cat >> /var/spool/cron/crontabs/root
*/5 * * * * /bin/run-parts /etc/cron.mrtg 1> /dev/null
Now you logon to your web browser http://192.168.0.1/mrtg/ and Now you should see CPU,Memory and Disk Usage graphs.
If you want more documentation about MRTG check here
linux | 评论:0
| Trackbacks:0
| 阅读:1354
Submitted by admin on 2011, July 7, 6:22 PM
http://www.oidview.com/mibs/3495/SQUID-MIB.html
squid/缓存 | 评论:0
| Trackbacks:0
| 阅读:1233
Submitted by admin on 2011, July 7, 9:04 AM
http://hi.baidu.com/wizardchilde/blog/item/5d5b8738ffebd236b9998f26.html
php | 评论:0
| Trackbacks:0
| 阅读:1264
Submitted by admin on 2011, July 7, 7:42 AM
1 TOP
这是一个大家经常问到的问题,例如在SQLSERVER中可以使用如下语句来取得记录集中的前十条记录:
SELECT TOP 10 * FROM [index] ORDER BY indexid DESC;
但是这条SQL语句在SQLite中是无法执行的,应该改为:
SELECT * FROM [index] ORDER BY indexid DESC limit 0,10;
其中limit 0,10表示从第0条记录开始,往后一共读取10条
2 创建视图(Create View)
SQLite在创建多表视图的时候有一个BUG,问题如下:
CREATE VIEW watch_single AS SELECT DISTINCTwatch_item.[watchid],watch_item.[itemid] FROM watch_item;
上面这条SQL语句执行后会显示成功,但是实际上除了
SELECT COUNT(*) FROM [watch_single ] WHERE watch_ single.watchid = 1;
能执行之外是无法执行其他任何语句的。其原因在于建立视图的时候指定了字段所在的表名,而SQLite并不能正确地识别它。所以上面的创建语句要改为:
CREATE VIEW watch_single AS SELECT DISTINCT [watchid],[itemid] FROM watch_item;
但是随之而来的问题是如果是多表的视图,且表间有重名字段的时候该怎么办?
3 COUNT(DISTINCT column)
SQLite在执行如下语句的时候会报错:
SELECT COUNT(DISTINCT watchid) FROM [watch_item] WHERE watch_item.watchid = 1;
其原因是SQLite的所有内置函数都不支持DISTINCT限定,所以如果要统计不重复的记录数的时候会出现一些麻烦。比较可行的做法是先建立一个不重复的记录表的视图,然后再对该视图进行计数。
4 外连接
虽然SQLite官方已经声称LEFT OUTER JOIN 已经实现,但还没有 RIGHT OUTER JOIN 和 FULL OUTER JOIN。但是实际测试表明似乎并不能够正常的工作。以下三条语句在执行的时候均会报错:
SELECT tags.[tagid] FROM [tags],[tag_rss] WHERE tags.[tagid] = tag_rss.[tagid](*);
SELECT tags.[tagid] FROM [tags],[tag_rss] WHERE LEFT OUTER JOIN tag_rss.[tagid] = tags.[tagid];
SELECT tags.[tagid] FROM [tags],[tag_rss] WHERE LEFT JOIN tag_rss.[tagid] = tags.[tagid];
此外经过测试用+号代替*号也是不可行的。
收集SQLite与Sql Server的语法差异
1.返回最后插入的标识值
返回最后插入的标识值sql server用@@IDENTITY
sqlite用标量函数LAST_INSERT_ROWID()
返回通过当前的 SQLConnection 插入到数据库的最后一行的行标识符(生成的主键)。此值与 SQLConnection.lastInsertRowID 属性返回的值相同。
2.top n
在sql server中返回前2行可以这样:
select top 2 * from aa
order by ids desc
sqlite中用LIMIT,语句如下:
select * from aa
order by ids desc
LIMIT 2
3.GETDATE ( )
在sql server中GETDATE ( )返回当前系统日期和时间
sqlite中没有
4.EXISTS语句
sql server中判断插入(不存在ids=5的就插入)
IF NOT EXISTS (select * from aa where ids=5)
BEGIN
insert into aa(nickname)
select 't'
END
在sqlite中可以这样
insert into aa(nickname)
select 't'
where not exists(select * from aa where ids=5)
5.嵌套事务
sqlite仅允许单个活动的事务
6.RIGHT 和 FULL OUTER JOIN
sqlite不支持 RIGHT OUTER JOIN 或 FULL OUTER JOIN
7.可更新的视图
sqlite视图是只读的。不能对视图执行 DELETE、INSERT 或 UPDATE 语句,sql server是可以对视图 DELETE、INSERT 或 UPDATE
mysql/db | 评论:0
| Trackbacks:0
| 阅读:1271
Submitted by admin on 2011, July 6, 7:10 PM
aufs存储机制已经发展到超出了改进squid磁盘I/O响应时间的最初尝试。"a"代表着异步I/O。默认的ufs和aufs之间的唯一区别,在于I/O是否被squid主进程执行。数据格式都是一样的,所以你能在两者之间轻松选择,而不用丢失任何cache数据。
aufs使用大量线程进行磁盘I/O操作。每次squid需要读写,打开关闭,或删除cache文件时,I/O请求被分派到这些线程之一。当线程完成了I/O后,它给squid主进程发送信号,并且返回一个状态码。实际上在squid2.5中,某些文件操作默认不是异步执行的。最明显的,磁盘写总是同步执行。你可以修改src/fs/aufs/store_asyncufs.h文件,将ASYNC_WRITE设为1,并且重编译squid。
aufs代码需要pthreads库。这是POSIX定义的标准线程接口。尽管许多Unix系统支持pthreads库,但我经常遇到兼容性问题。aufs存储系统看起来仅仅在Linux和Solaris上运行良好。在其他操作系统上,尽管代码能编译,但也许会面临严重的问题。
为了使用aufs,可以在./configure时增加一个选项:
% ./configure --enable-storeio=aufs,ufs
严格讲,你不必在storeio模块列表中指定ufs。然而,假如你以后不喜欢aufs,那么就需要指定ufs,以便能重新使用稳定的ufs存储机制。
假如愿意,你也能使用—with-aio-threads=N选项。假如你忽略它,squid基于aufs cache_dir的数量,自动计算可使用的线程数量。表8-1显示了1-6个cache目录的默认线程数量。
Table 8-1. Default number of threads for up to six cache directories
cache_dirs Threads
1 16
2 26
3 32
4 36
5 40
6 44
将aufs支持编译进squid后,你能在squid.conf文件里的cache_dir行后指定它:
cache_dir aufs /cache0 4096 16 256
在激活了aufs并启动squid后,请确认每件事仍能工作正常。可以运行tail -f store.log一会儿,以确认缓存目标被交换到磁盘。也可以运行tail -f cache.log并且观察任何新的错误或警告。
8.4.1 aufs如何工作
Squid通过调用pthread_create来创建大量的线程。所有线程在任何磁盘活动之上创建。这样,即使squid空闲,你也能见到所有的线程。
无论何时,squid想执行某些磁盘I/O操作(例如打开文件读),它分配一对数据结构,并将I/O请求放进队列中。线程循环读取队列,取得I/O请求并执行它们。因为请求队列共享给所有线程,squid使用独享锁来保证仅仅一个线程能在给定时间内更新队列。
I/O操作阻塞线程直到它们被完成。然后,将操作状态放进一个完成队列里。作为完整的操作,squid主进程周期性的检查完成队列。请求磁盘I/O的模块被通知操作已完成,并获取结果。
你可能已猜想到,aufs在多CPU系统上优势更明显。唯一的锁操作发生在请求和结果队列。然而,所有其他的函数执行都是独立的。当主进程在一个CPU上执行时,其他的CPU处理实际的I/O系统调用。
8.4.2 aufs发行
线程的有趣特性是所有线程共享相同的资源,包括内存和文件描述符。例如,某个线程打开一个文件,文件描述符为27,所有其他线程能以相同的文件描述符来访问该文件。可能你已知道,在初次管理squid时,文件描述符短缺是较普遍问题。Unix内核典型的有两种文件描述符限制:
进程级的限制和系统级的限制。你也许认为每个进程拥有256个文件描述符足够了(因为使用线程),然而并非如此。在这样的情况下,所有线程共享少量的文件描述符。请确认增加系统的进程文件描述符限制到4096或更高,特别在使用aufs时。
调整线程数量有点棘手。在某些情况下,可在cache.log里见到如下警告:
2003/09/29 13:42:47| squidaio_queue_request: WARNING - Disk I/O overloading
这意味着squid有大量的I/O操作请求充满队列,等待着可用的线程。你首先会想到增加线程数量,然而我建议,你该减少线程数量。
增加线程数量也会增加队列的大小。超过一定数量,它不会改进aufs的负载能力。它仅仅意味着更多的操作变成队列。太长的队列导致响应时间变长,这绝不是你想要的。
减少线程数量和队列大小,意味着squid检测负载条件更快。当某个cache_dir超载,它会从选择算法里移除掉(见7.4章)。然后,squid选择其他的cache_dir或简单的不存储响应到磁盘。这可能是较好的解决方法。尽管命中率下降,响应时间却保持相对较低。
8.4.3 监视aufs操作
Cache管理器菜单里的Async IO Counters选项,可以显示涉及到aufs的统计信息。它显示打开,关闭,读写,stat,和删除接受到的请求的数量。例如:
% squidclient mgr:squidaio_counts
...
ASYNC IO Counters:
Operation # Requests
open 15318822
close 15318813
cancel 15318813
write 0
read 19237139
stat 0
unlink 2484325
check_callback 311678364
queue 0
取消(cancel)计数器正常情况下等同于关闭(close)计数器。这是因为close函数总是调用cancel函数,以确认任何未决的I/O操作被忽略。
写(write)计数器为0,因为该版本的squid执行同步写操作,即使是aufs。
check_callbak计数器显示squid主进程对完成队列检查了多少次。
queue值显示当前请求队列的长度。正常情况下,队列长度少于线程数量的5倍。假如你持续观察到队列长度大于这个值,说明squid配得有问题。增加更多的线程也许有帮助,但仅仅在特定范围内。
squid/缓存 | 评论:0
| Trackbacks:0
| 阅读:1378
Submitted by admin on 2011, July 5, 10:22 PM
一、 LVS简介
LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项目,它的官方站点是www.linuxvirtualserver.org。现在LVS已经是 Linux标准内核的一部分,在Linux2.4内核以前,使用LVS时必须要重新编译内核以支持LVS功能模块,但是从Linux2.4内核以后,已经完全内置了LVS的各个功能模块,无需给内核打任何补丁,可以直接使用LVS提供的各种功能。使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。
关于LVS的安装与介绍,在前面的文章中已经有过深入介绍,这里不再讲述。
本文讲解的环境如下:
操作系统:统一采用Centos5.3版本,地址规划如下:
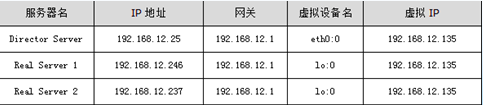
图1
图1中的VIP指的是虚拟IP地址,还可以叫做LVS集群的服务IP,在DR、TUN模式中,数据包是直接返回给用户的,所以,在Director Server上以及集群的每个节点上都需要设置这个地址。此IP在Real Server上一般绑定在回环地址上,例如lo:0,同样,在Director Server上,虚拟IP绑定在真实的网络接口设备上,例如eth0:0。
各个Real Server可以是在同一个网段内,也可以是相互独立的网段,还可以是分布在internet上的多个服务器.
LVS+Keepalived高可用负载均衡集群拓扑结构如图2所示:
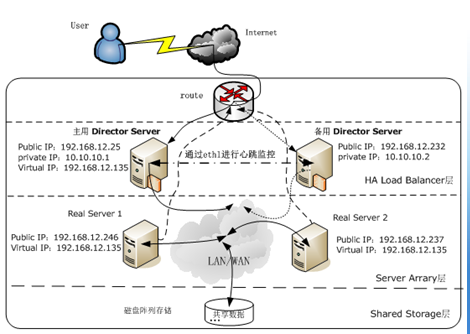
图2
二、安装Keepalived
keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,后来又加入了VRRP的功能,VRRP是Virtual Router Redundancy Protocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由出现的单点故障问题,它能够保证网络的不间断、稳定的运行。所以,keepalived一方面具有服务器健康检测功能,另一方面也具有HA cluster功能。
Keepalived的官方站点是http://www.keepalived.org,可以在这里下载到各种版本,我们这里下载的是keepalived-1.1.19.tar.gz,安装步骤如下:
[root@DR1 ~]#tar zxvf keepalived-1.1.19.tar.gz
[root@DR1 ~]#cd keepalived-1.1.19
[root@DR1 keepalived-1.1.19]#./configure --sysconf=/etc \
> --with-kernel-dir=/usr/src/kernels/2.6.18-8.el5-i686
[root@DR1 keepalived-1.1.19]#make
[root@DR1 keepalived-1.1.19]#make install
[root@DR1 keepalived-1.1.19]#ln -s /usr/local/sbin/keepalived /sbin/
在编译选项中,“--sysconf”指定了Keepalived配置文件的安装路径,即路径为/etc/Keepalived/Keepalived.conf,“--with-kernel-dir”这是个很重要的参数,但这个参数并不是要把Keepalived编译进内核,而是指定使用内核源码里面的头文件,就是include目录。如果要使用LVS时,才需要用到此参数,否则是不需要的.
三、配置Keepalived
Keepalived的配置非常简单,仅仅需要一个配置文件即可完成HA cluster和lvs服务节点监控功能,Keepalived的安装已经在上面章节进行了介绍,在通过Keepalived搭建高可用的LVS集群实例中,主、备Director Server都需要安装Keepalived软件,安装成功后,默认的配置文件路径为/etc/Keepalived/Keepalived.conf。一个完整的keepalived配置文件,有三个部分组成,分别是全局定义部分、vrrp实例定义部分以及虚拟服务器定义部分,下面详细介绍下这个配置文件中每个选项的详细含义和用法:
#全局定义部分
global_defs {
notification_email {
dba.gao@gmail.com #设置报警邮件地址,可以设置多个,每行一个。注意,如果要开启邮件报警,需要开启本机的sendmail服务。
ixdba@163.com
}
notification_email_from Keepalived@localhost #设置邮件的发送地址。
smtp_server 192.168.200.1 #设置smtp server地址。
smtp_connect_timeout 30 #设置连接smtp服务器超时时间。
router_id LVS_MASTER #运行Keepalived服务器的一个标识。发邮件时显示在邮件标题中的信息
}
#vrrp实例定义部分
vrrp_instance VI_1 {
state MASTER #指定Keepalived的角色,MASTER表示此主机是主用服务器,BACKUP表示是备用服务器。
interface eth0 #指定HA监测网络的接口。
virtual_router_id 51 #虚拟路由标识,这个标识是一个数字,并且同一个vrrp实例使用唯一的标识,即同一个vrrp_instance下,MASTER和BACKUP必须是一致的。
priority 100 #定义优先级,数字越大,优先级越高,在一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级。
advert_int 1 #设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒。
authentication { #设定验证类型和密码。
auth_type PASS #设置验证类型,主要有PASS和AH两种。
auth_pass 1111 #设置验证密码,在一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信。
}
virtual_ipaddress { #设置虚拟IP地址,可以设置多个虚拟IP地址,每行一个。
192.168.12.135
}
}
#虚拟服务器定义部分
virtual_server 192.168.12.135 80 { #设置虚拟服务器,需要指定虚拟ip地址和服务端口,ip与端口之间用空格隔开。
delay_loop 6 #设置健康检查时间,单位是秒。
lb_algo rr #设置负载调度算法,这里设置为rr,即轮询算法。
lb_kind DR #设置LVS实现负载均衡的机制,可以有NAT、TUN和DR三个模式可选。
persistence_timeout 50 #会话保持时间,单位是秒,这个选项对于动态网页是非常有用的,为集群系统中session共享提供了一个很好的解决方案。有了这个会话保持功能,用户的请求会被一直分发到某个服务节点,直到超过这个会话保持时间。需要注意的是,这个会话保持时间,是最大无响应超时时间,也就是说用户在操作动态页面时,如果在50秒内没有执行任何操作,那么接下来的操作会被分发到另外节点,但是如果一直在操作动态页面,则不受50秒的时间限制。
protocol TCP #指定转发协议类型,有tcp和udp两种。
real_server 192.168.12.246 80 { #配置服务节点1,需要指定real server的真实IP地址和端口,ip与端口之间用空格隔开。
weight 3 #配置服务节点的权值,权值大小用数字表示,数字越大,权值越高,设置权值的大小可以为不同性能的服务器分配不同的负载,可以对性能高的服务器设置较高的权值,而对性能较低的服务器设置相对较低的权值,这样就合理的利用和分配了系统资源。
TCP_CHECK { #realserve的状态检测设置部分,单位是秒
connect_timeout 10 #10秒无响应超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试间隔
}
}
real_server 192.168.12.237 80 { #配置服务节点2
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
在配置Keepalived.conf时,需要特别注意配置文件的语法格式,因为Keepalived在启动时并不检测配置文件的正确性,即使没有配置文件,Keepalived也照样能启动起来,因而配置文件一定要正确。
在默认情况下,Keepalived在启动时会查找/etc/Keepalived/Keepalived.conf配置文件,如果你的配置文件放在了其它路径下,可以通过“Keepalived -f”参数指定你所在的配置文件路径即可。
Keepalived.conf配置完毕后,将此文件拷贝到备用Director Server对应的路径下,然后做两个简单的修改即可:
将“state MASTER”更改为“state BACKUP”
将priority 100更改为一个较小的值,这里改为“priority 80”
最后,还要配置集群的Real server节点,以达到与Director Server相互广播通信并忽略arp的目的,脚本的内容已经在前面文章中进行过介绍,这里不做解释。
集群/分流 | 评论:0
| Trackbacks:0
| 阅读:1479
Submitted by admin on 2011, July 5, 10:21 PM
一个功能比较完整的keepalived的配置文件,其配置文件keepalived.conf可以包含三个文本块:全局定义块、VRRP实例定义块及虚拟服务器定义块。全局定义块和虚拟服务器定义块是必须的,如果在只有一个负载均衡器的场合,就不须VRRP实例定义块。
接下来,我们以一个配置文件模版为例,有选择的说明其中一些重要项的功能或作用。
● 全局定义块
1、 email通知。作用:有故障,发邮件报警。这是可选项目,建议不用,用nagios全面监控代替之。
2、 Lvs负载均衡器标识(lvs_id)。在一个网络内,它应该是唯一的。
3、 花括号“{}”。用来分隔定义块,因此必须成对出现。如果写漏了,keepalived运行时,不会得到预期的结果。由于定义块内存在嵌套关系,因此很容易遗漏结尾处的花括号,这点要特别注意。
● VRRP定义块
1、 同步vrrp组vrrp_sync_group。作用:确定失败切换(FailOver)包含的路由实例个数。即在有2个负载均衡器的场景,一旦某个负载均衡器失效,需要自动切换到另外一个负载均衡器的实例是哪些?
2、 实例组group.至少包含一个vrrp实例。
3、 Vrrp实例vrrp_instance.实例名出自实例组group所包含的那些名字。
(1) 实例状态state.只有MASTER和BACKUP两种状态,并且需要大写这些单词。其中MASTER为工作状态,BACKUP为备用状态。当MASTER所在的服务器失效时,BACKUP所在的系统会自动把它的状态有BACKUP变换成MASTER;当失效的MASTER所在的系统恢复时,BACKUP从MASTER恢复到BACKUP状态。
(2) 通信接口interface。对外提供服务的网络接口,如eth0,eth1.当前主流的服务器都有2个或2个以上的接口,在选择服务接口时,一定要核实清楚。
(3) lvs_sync_daemon_inteface。负载均衡器之间的监控接口,类似于HA HeartBeat的心跳线。但它的机制优于Heartbeat,因为它没有“裂脑”这个问题,它是以优先级这个机制来规避这个麻烦的。在DR模式中,lvs_sync_daemon_inteface 与服务接口interface 使用同一个网络接口。
(4) 虚拟路由标识virtual_router_id.这个标识是一个数字,并且同一个vrrp实例使用唯一的标识。即同一个vrrp_stance,MASTER和BACKUP的virtual_router_id是一致的,同时在整个vrrp内是唯一的。
(5) 优先级priority.这是一个数字,数值愈大,优先级越高。在同一个vrrp_instance里,MASTER 的优先级高于BACKUP。若MASTER的priority值为150,那么BACKUP的priority只能是140或更小的数值。
(6) 同步通知间隔 advert_int .MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位为秒。
(7) 验证authentication。包含验证类型和验证密码。类型主要有PASS、AH两种,通常使用的类型为PASS,据说AH使用时有问题。验证密码为明文,同一vrrp实例MASTER与BACKUP 使用相同的密码才能正常通信。
4、 虚拟ip地址virtual_ipaddress . 可以有多个地址,每个地址占一行,不需要指定子网掩码。注意:这个ip必须与我们在lvs客户端设定的vip相一致!
● 虚拟服务器virtual_server定义块
虚拟服务器定义是keepalived框架最重要的项目了,是keepalived.conf必不可少的部分。
1、 虚拟服务器virtual_server. 这个ip来自于vrrp定义块的第“4”步,后面一个空格,然后加上端口号。定义一个vip,可以实现多个tcp端口的负载均衡功能。
(1) delay_loop。健康检查时间间隔,单位是秒。
(2) lb_algo. 负载均衡调度算法,互联网应用常使用wlc或rr。
(3) lb_kind. 负载均衡转发规则。一般包括DR,NAT,TUN3种,在我的方案中,都使用DR的方式。
(4) persistence_timeout.会话保持时间,单位是秒。这个选项对动态网站很有用处:当用户从远程用帐号进行登陆网站时,有了这个会话保持功能,就能把用户的请求转发给同一个应用服务器。在这里,我们来做一个假设,假定现在有一个lvs 环境,使用DR转发模式,真实服务器有3个,负载均衡器不启用会话保持功能。当用户第一次访问的时候,他的访问请求被负载均衡器转给某个真实服务器,这样他看到一个登陆页面,第一次访问完毕;接着他在登陆框填写用户名和密码,然后提交;这时候,问题就可能出现了—登陆不能成功。因为没有会话保持,负载均衡器可能会把第2次的请求转发到其他的服务器。
(5) 转发协议protocol.一般有tcp和udp两种。实话说,我还没尝试过udp协议类的转发。
2、 真实服务器real_server.也即服务器池。Real_server的值包括ip地址和端口号。多个连续的真实ip,转发的端口相同,是不是可以以范围表示?需要进一步实验。如写成real_server 61.135.20.1-10 80 .
(1) 权重weight.权重值是一个数字,数值越大,权重越高。使用不同的权重值的目的在于为不同性能的机器分配不同的负载,性能较好的机器,负载分担大些;反之,性能差的机器,则分担较少的负载,这样就可以合理的利用不同性能的机器资源。
(2) Tcp检查 tcp_check.
集群/分流 | 评论:0
| Trackbacks:0
| 阅读:1657
Submitted by admin on 2011, July 4, 8:13 PM
TCP_IMS_HIT:NONE 客户端发送确认请求,Squid发现更近来的、新鲜的请求资源的拷贝。
Squid发送更新的内容到客户端,而不联系原始服务器。(这指明Squid对本次请求,不会与任何其他服务器(邻居或原始服务器)通信。)
TCP_MEM_HIT:NONE 类似 TCP_IMS_HIT:NONE, 从内存中响应
TCP_REFRESH_HIT:FIRST_UP_PARENT/d
Squid发现请求资源的貌似陈旧的拷贝,并发送确认请求到原始服务器。
原始服务器返回304(未修改)响应,指示squid的拷贝仍旧是新鲜的。或者是重新更新文件。(Squid直接转发请求到原始服务器)
#######2011-03-22 http206 test###
refresh_pattern -i \.exe 60 80% 1440 ignore-reload
maximum_object_size 60 MB
range_offset_limit -1
#################################
range_offset_limit这个参数,主要是对各种流媒体和要断点续传的文件的缓存的。 默认是 是
range_offset_limit 0
squidclient -t 1 -h 127.0.0.1 -p 80 mgr:info
/usr/local/squid/bin/squidclient -p80 -m PURGE URL
squid/缓存 | 评论:0
| Trackbacks:0
| 阅读:1768
